



Phoenix WinNonlin’s integrated tools make it easy to perform non-compartmental pharmacokinetic analysis (NCA) and create plots and well-organized tables that can be easily customized to your drug program’s unique specifications. You can drag and drop new data into an existing workflow or update input data to generate up-to-date results effortlessly. Here are a few tips and tricks that will help you add categorical covariates to your models and run individual and population PK simulations.
Individual vs. population models in pharmacokinetics
Pharmacokinetic (PK) modeling and simulation can be used to predict the pharmacokinetic behavior of a drug in both an individual and a population. Individual simulations are based on data from a single subject, while population simulations are based on data from multiple patients.
Individual PK analysis requires intensive PK sampling per subject (human or animal). NCA analysis is often used to describe the PK of individual data because it’s a quick and reproducible method. Compartmental models can also be fit to individual PK data utilizing all the data available for an individual and providing a better understanding of the PK processes including the absorption phase. However, predictions from individual PK analyses may not be relevant to patients that differ from the sampled individuals.
Population PK analysis uses both intensive and sparse sampling, and it evaluates an entire study population accounting for differences across individuals in the population (i.e., covariates). The analysis time is longer, and the final model could depend on the sequence of the decisions made by the analyst during model selection. However, a qualified population PK model can be useful to make predictions for the population and understand how individuals from a population differ from one another.
What are covariates, and why are they so important?
Covariates can be used to control for confounding variables (variables that affect the outcome of a pharmacokinetic (PK) study but are not being studied). In other words, they can help ensure that the results of a study are not due to extraneous factors. For example, if you want to study the effect of a new drug on patient outcomes, you will want to control for factors such as age, gender, and underlying health conditions. By controlling for these variables, you can be more confident that any differences in health outcomes are due to the new medication and not to other factors.
Adding categorical covariates to your Phoenix model
When fitting a population model in Phoenix NLME, you can add covariates to your model without having to recode the covariate values. The steps to evaluate covariates in your model is to first duplicate your base model without covariates. and then change the settings to include covariates in the duplicate model. To do this, go to the “Parameters” tab and select “Add From Unused.” The system will display all the columns in the input dataset that have not been mapped in the model. Select the covariates that you would like to use.
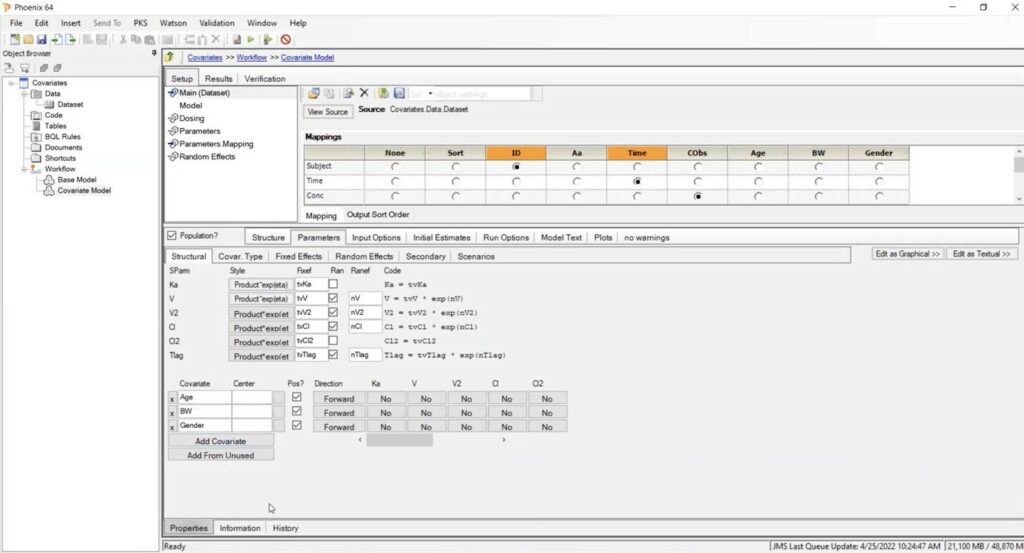
The model will assume that all the covariates are continuous variables like age. However, the user can indicate which covariates, such as gender, are categorial. The engines that perform population analysis require categorial covariates to be coded as integers (e.g., 0 and 1). Phoenix converts categorical covariates to numerical values without user re-coding them. Go to the “Covariate Type” subtab and check the “Allow Arbitrary Category Names” box.
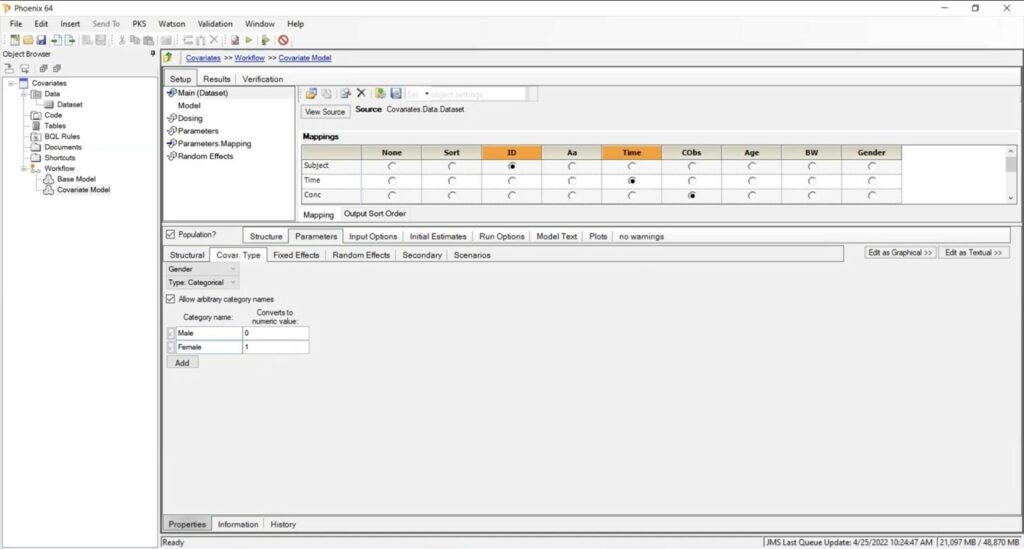
Type the name of the categories that exist in the data and then assign a number to each one. For example, assign a value of 0 to males and 1 to females. Execute, and you will see that the results change to show the use of the covariates.
Check out this video to learn more about using categorical covariates in your Phoenix models.
Individual PK simulations
Phoenix allows you to run PK simulations both in individual and population modes. To run an individual simulation, there is no need to identify every single time point in your simulation. Instead you can start with a worksheet that indicates the dosing regimen with just a few lines utilizing the concept of additional doses (ADDL) [See section “Running a dose simulation using ADDL]. Send the worksheet to a model. The model should be set up with the “Population” box left unchecked. This will run the model in individual mode. Then you can begin to apply your mappings.
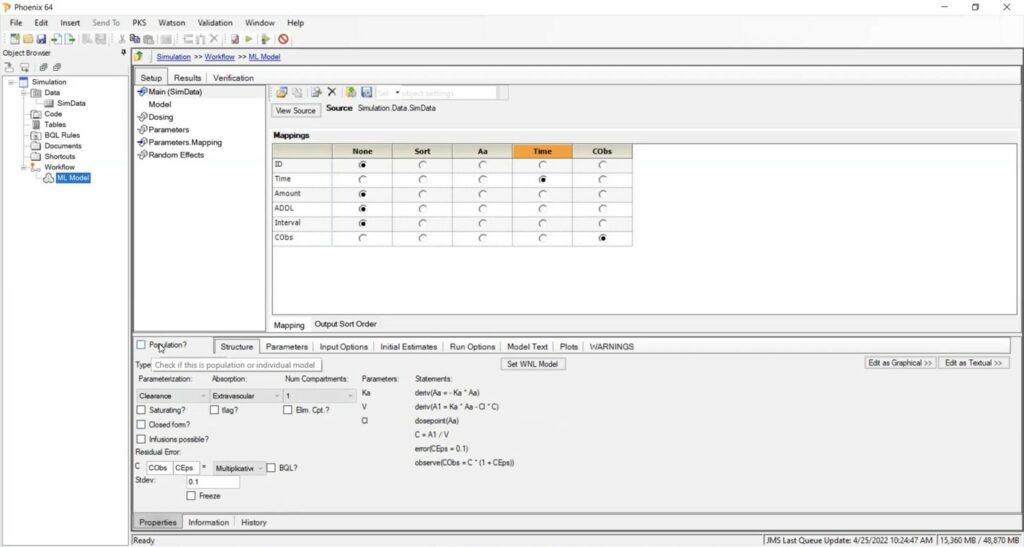
To add multiple dose information, go to the “Input Options” tab and check the “Additional Dose Information” (ADDL) box. Then go to the “Run Options” tab and check the “Simulation” box.
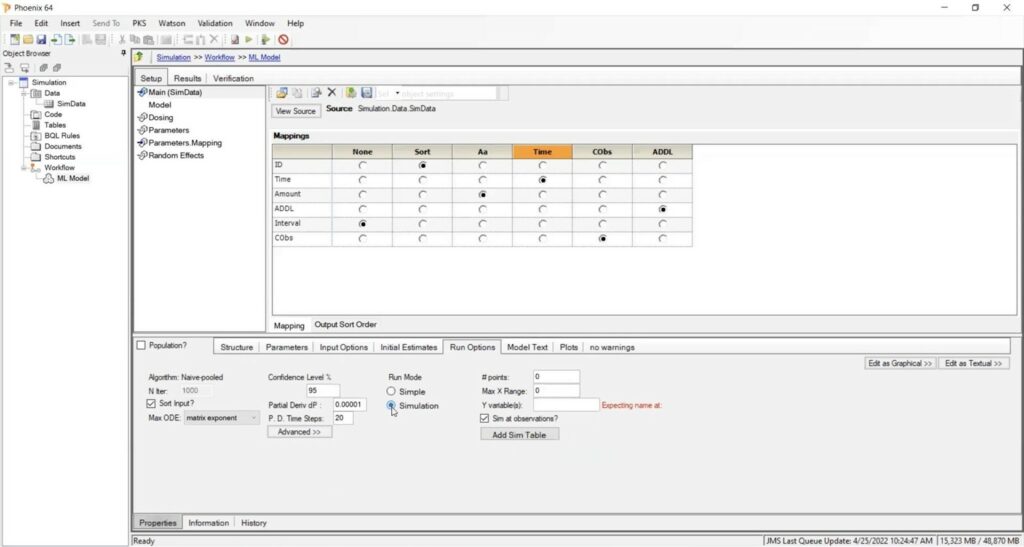
Next, under the “Parameters” tab, click on “Fixed Effects,” enter your model parameters and execute. In the “Results” tab, you will then be able to look at the individual simulation and the table of data that was generated.
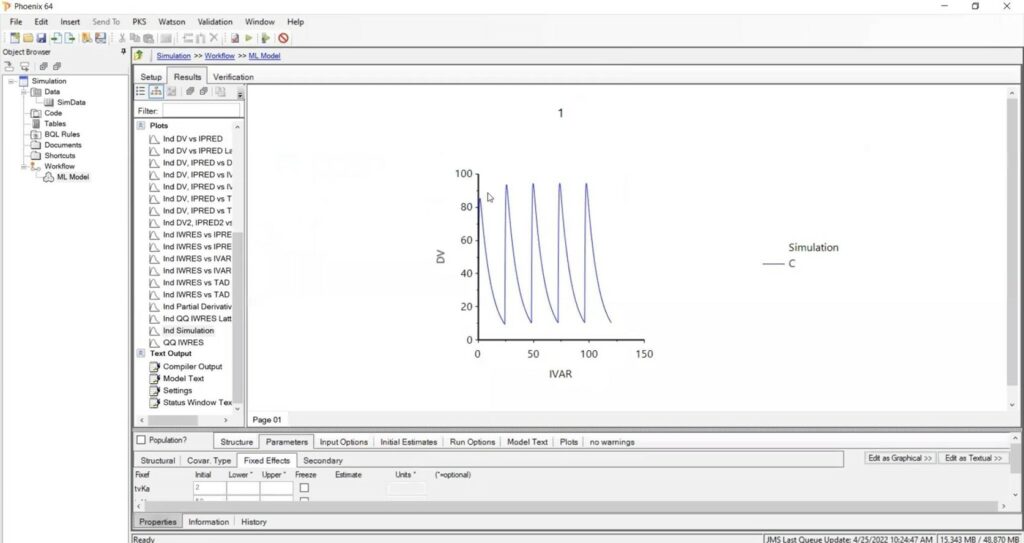
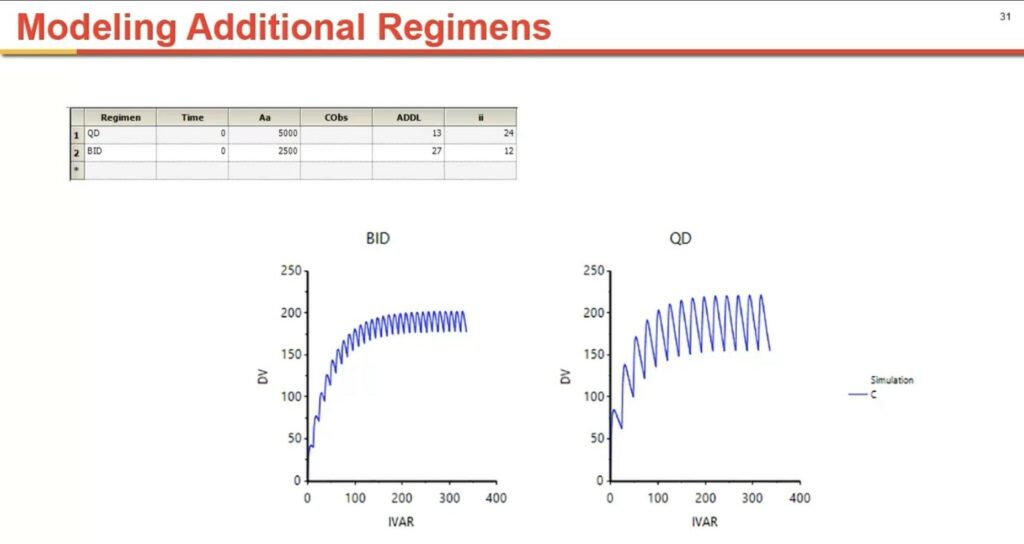
You can add rows to your spreadsheet to get additional information even after running your simulation. For example, you can look at the effects of QD vs. BID dosing by simply adding a BID row and repeating the execution.
Are you having trouble setting up your individual PK simulations? This video can help.
Population PK simulations
To run a PK simulation in population mode, first create a population model and then use it to perform the simulation. Take the model, copy it, and paste it into the project with a new name.
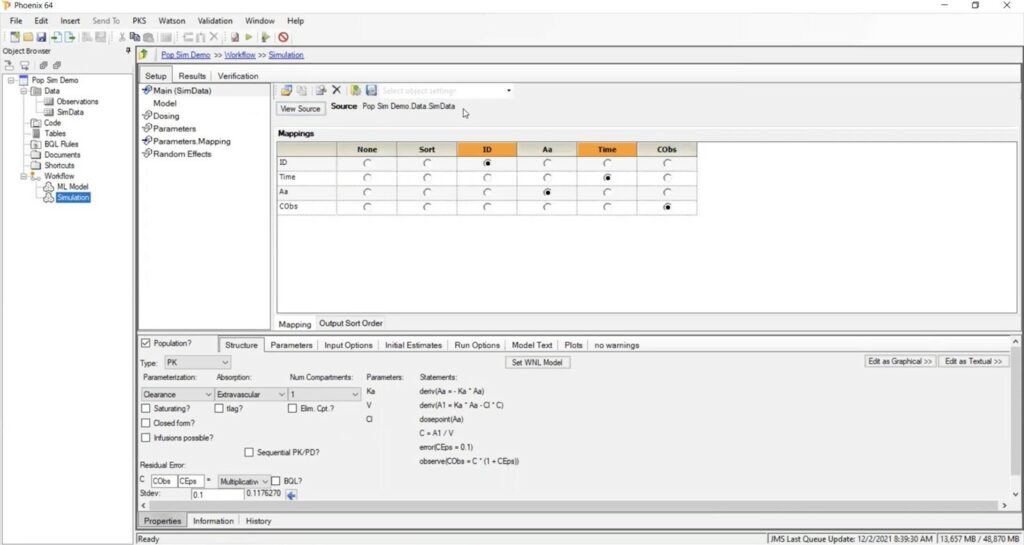
Go to the “Parameters” tab and then open the “Fixed Effects” subtab. Select “Accept All Fixed and Random” to copy all the fixed and random effects data estimated from the final model fit.
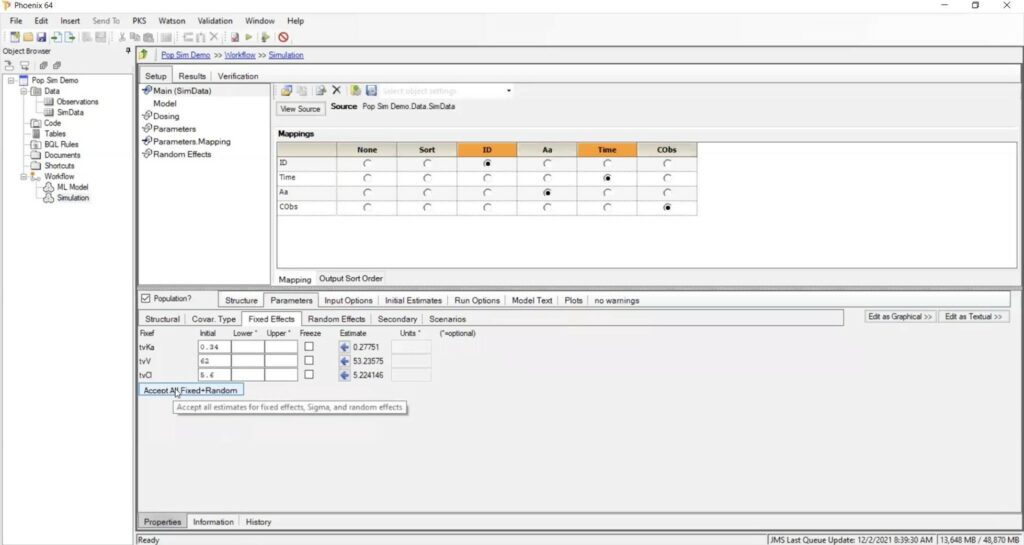
Go to the “Run options” tab and select “Simulation.” You then enter the number of replicates that you want to have in the simulation.
Phoenix simulation mode will generate tables that can then be examined visually in graphs.
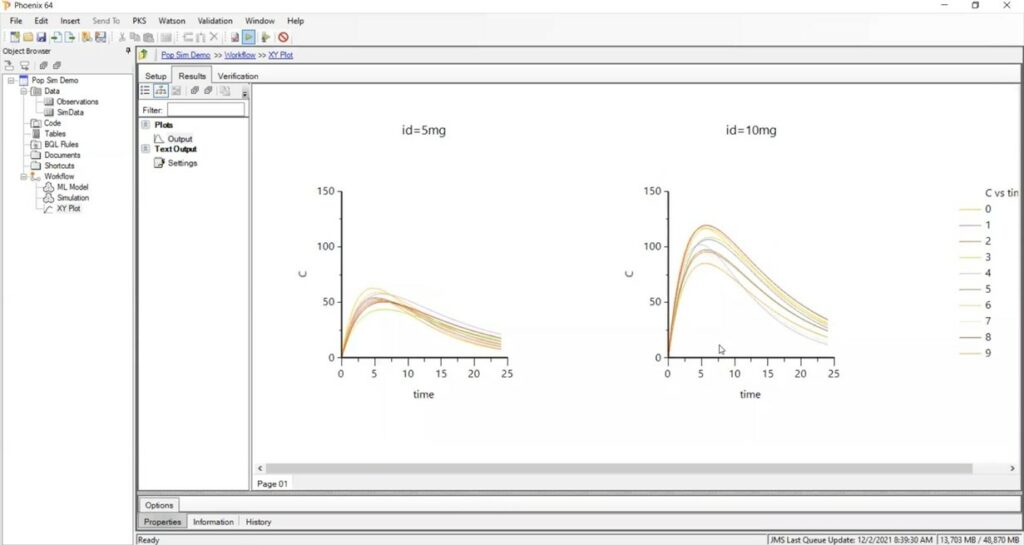
Want more tips on running population simulations? This video gives you detailed information.
Running a dosing simulation using ADDL
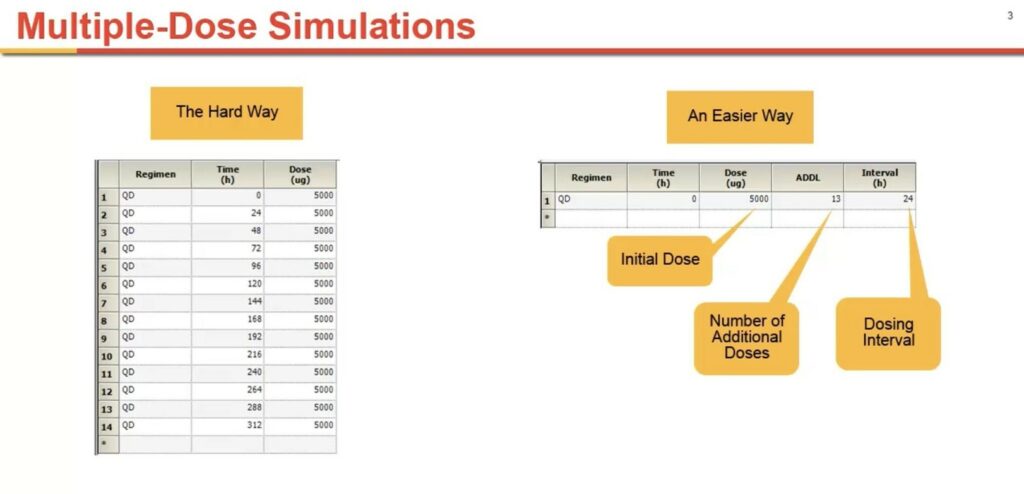
Phoenix lets you easily use the estimated parameter values from a model fit to single dose data to simulate repeat dosing to predict concentrations that will be obtained at steady state. There are two ways to create these simulations: One way is to create a worksheet with all the time and dose values, with a row for each individual dose. If you want to modify the dosing regimen, you must change many values in the worksheet. This can be very time-consuming.
There is a much easier way. You only need to have one row for the initial dose at time zero. You add a column called “ADDL,” which is the number of additional doses and the dosing interval.
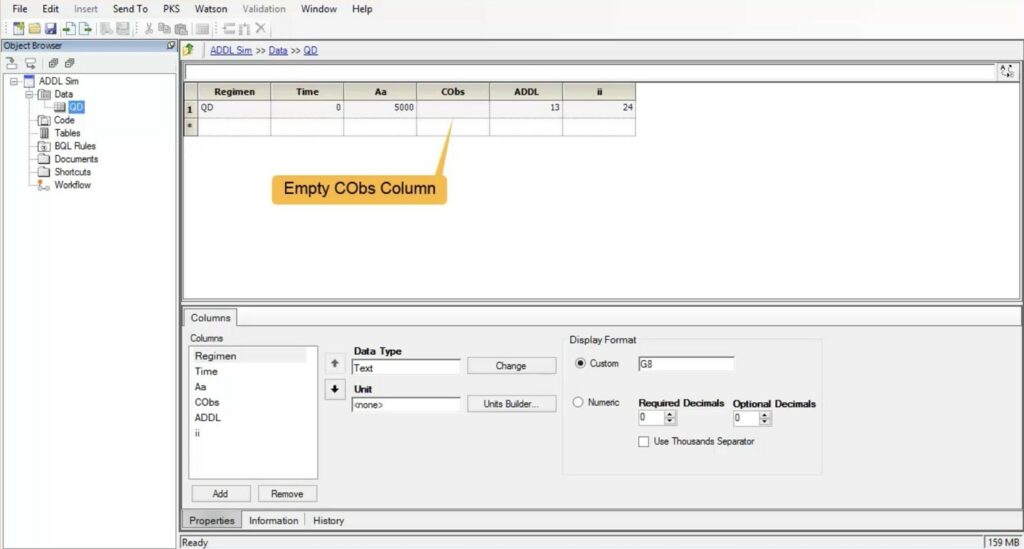
Start with a similar worksheet with columns for the dose amount ADDL and the dosing interval. You also include the empty CObs column, which eliminates the message that there are no observations mapped. For example, in the worksheet above with one line you are indicating that a dose of 5000ug was given at time 0 and then it was given 13 more times every 24 hours. Start by sending this worksheet to your Phoenix model and set the model structure to match results from prior studies. Make sure that your column names match the mappings so that your column will be mapped automatically.
You will also map the Regimen to Sort. Select the “Parameters” tab to select the parameters to use in the simulation. Enter the parameters in the “Fixed Effect” subtab. By default, the parameter estimates are all equal to one.
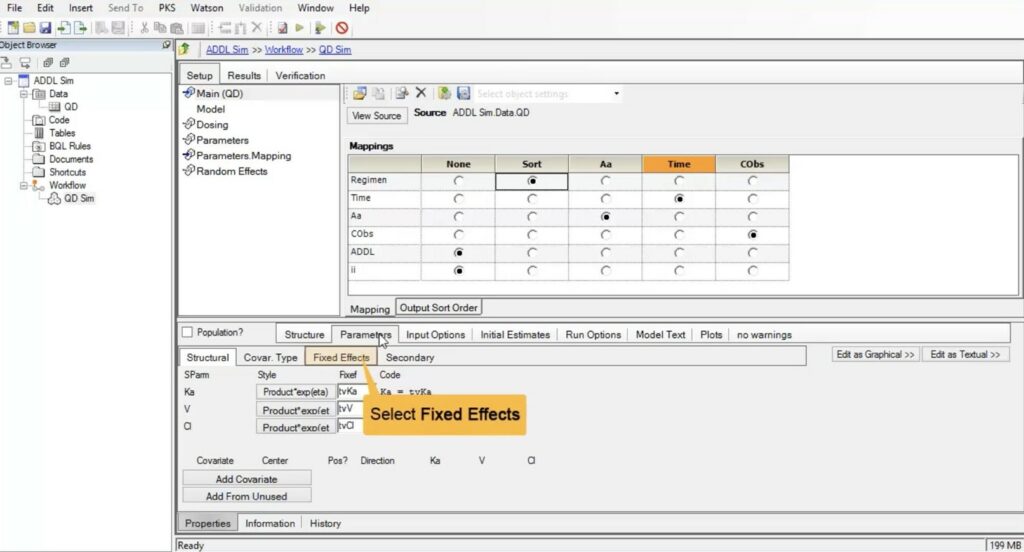
Enter the parameter values that you obtained from your previous model. Go to the “Input Options” tab. Here is where you enter the multiple dosing information. Check the “ADDL” box and then specify your dosing regimen you wish to simulate.
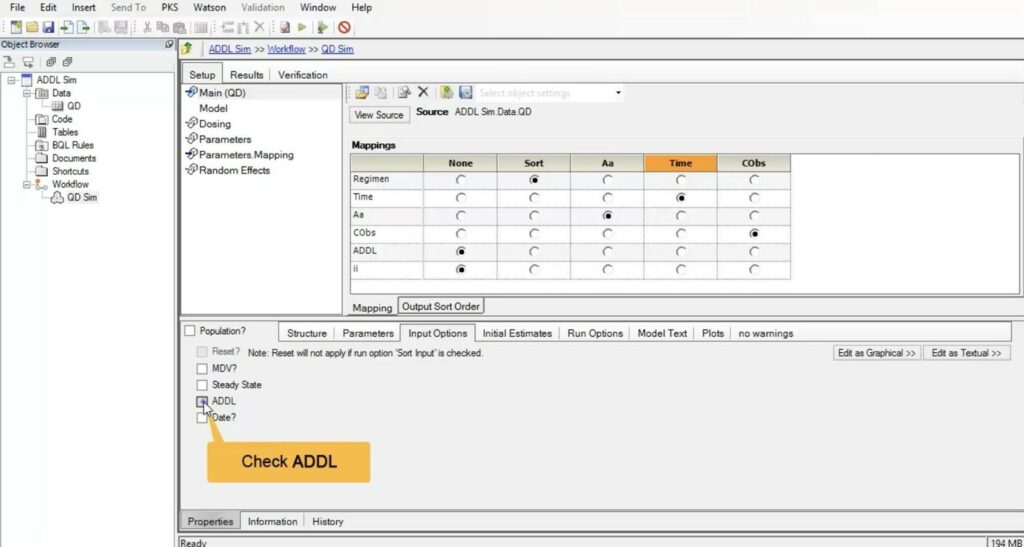
Next, go to the “Run Options” tab and select the “Simulation” mode. and execute the model. The output will be in a table as well as in the individual simulation plot. This approach can easily be extended to additional dosing regimens. For example, you can add a second row to the input worksheet and run simulations for both QD and BID dosing.
Check out this video for more detailed instructions on running a dosing simulation using ADDL.
Expand your knowledge & certify your skills
Learn valuable tips and tricks to master Phoenix software through our Certara University e-learning and certification courses.
